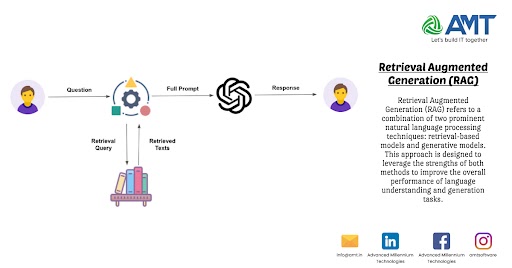
Retrieval Augmented Generation (RAG) refers to a combination of two prominent natural language processing techniques: retrieval-based models and generative models. This approach is designed to leverage the strengths of both methods to improve the overall performance of language understanding and generation tasks.
- Retrieval-Based Models:
- Purpose: These models focus on retrieving relevant information from a predefined set of documents or a knowledge base.
- Strengths: Efficient at extracting specific and accurate information, especially when the required knowledge is available in a structured format.
- Examples: Information retrieval systems, document-based question answering models.
- Generative Models:
- Purpose: These models aim to generate human-like text based on learned patterns and contexts, often utilizing deep learning architectures like transformers.
- Strengths: Capable of creative text generation and handling open-ended questions, but may struggle with accuracy and specificity in certain contexts.
- Examples: GPT (Generative Pre-trained Transformer) models, such as GPT-3.
Combining Retrieval and Generation:
- In Retrieval Augmented Generation, the retrieval-based models are used to identify and fetch relevant information from a knowledge base or a set of documents.
- The generative models then take this retrieved information and use it as context to generate coherent and contextually relevant responses or content.
Applications:
- Question Answering: RAG models can excel in question answering tasks by first retrieving relevant passages and then generating concise answers.
- Content Creation: They can be employed to generate content based on retrieved information, ensuring accuracy and relevance.
- Conversational Agents: In chatbots or virtual assistants, RAG models can enhance their ability to provide informative and context-aware responses.
Challenges:
- Integration: Ensuring a seamless integration of retrieval and generation components is crucial for the success of RAG models.
- Training Complexity: Training such models may require a careful balance between the two components to avoid biases or inconsistencies.
Notable implementations of this concept include models like DPR (Deep Pre-trained Representations) for retrieval and models like T5 or GPT for generation, working together to achieve more robust and contextually aware language understanding and generation.
Let’s delve a bit deeper into Retrieval Augmented Generation (RAG) models:
- Architecture:
- Retrieval Component: Typically, a retrieval-based model is used to select relevant passages or documents from a knowledge base. This could involve techniques like sparse retrieval, dense retrieval, or a combination of both.
- Generation Component: The generative model then takes the retrieved information as input and generates the final output. This can be achieved using transformer-based architectures, recurrent neural networks, or other sequence-to-sequence models.
- Fine-Tuning and Pre-training:
- RAG models often involve a two-step training process. The retrieval component is usually pre-trained on a large corpus to understand contextual representations. The generation component can be pre-trained separately.
- Fine-tuning is then performed on specific tasks or domains to adapt the model to the target application. This fine-tuning process may involve jointly training both components to work together effectively.
- Datasets and Evaluation:
- Datasets for training and evaluation of RAG models often include a combination of generative tasks (e.g., language modeling) and retrieval tasks (e.g., document retrieval, question answering).
- Evaluation metrics may include traditional metrics like BLEU (for language generation) and precision/recall/F1-score (for retrieval).
- Open-Domain Question Answering:
- RAG models are particularly useful in open-domain question answering scenarios, where the model needs to answer questions that may not have a fixed set of answers or may require external knowledge.
- Scalability:
- One advantage of RAG models is their potential scalability. The retrieval component can be designed to efficiently handle large knowledge bases, and the generative component can scale to generate coherent responses.
- Real-world Applications:
- RAG models find applications in various domains such as healthcare, customer support, education, and more. For instance, in a healthcare context, a model could retrieve relevant medical information and generate explanations or advice for specific queries.
- Hybrid Approaches:
- Some implementations might involve a hybrid approach where the retrieval component is not a separate module but integrated directly into the architecture of the generative model. This ensures a more seamless interaction between the two components.
- Ethical Considerations:
- Like any advanced AI system, RAG models raise ethical considerations, including potential biases present in the training data, responsible use of information retrieval, and the need for transparency in how the models operate.
In summary, Retrieval Augmented Generation represents a powerful approach to tackle the challenges of language understanding and generation by combining the strengths of retrieval-based and generative models. Ongoing research and advancements in this area are likely to further refine the capabilities and applications of these models.
Above is a brief about Retrieval Augmented Generation. Watch this space for more updates on the latest trends in Technology.