
Apache Kafka is an open-source stream processing platform developed by the Apache Software Foundation written in Scala and Java. The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds. Its storage layer is essentially a “massively scalable pub/sub message queue architect-ed as a distributed transaction log,” making it highly valuable for enterprise infrastructures to process streaming data.
Additionally, Kafka connects to external systems (for data import/export) via Kafka Connect and provides Kafka Streams, a Java stream processing library.
It gets used for two broad classes of application:
- Building real-time streaming data pipelines that reliably get data between systems or applications
- Building real-time streaming applications that transform or react to the streams of data
Kafka stores messages which come from arbitrarily many processes called “producers”. The data can thereby be partitioned in different “partitions” within different “topics”. Within a partition the messages are indexed and stored together with a time-stamp. Other processes called “consumers” can query messages from partitions. Kafka runs on a cluster of one or more servers and the partitions can be distributed across cluster nodes.
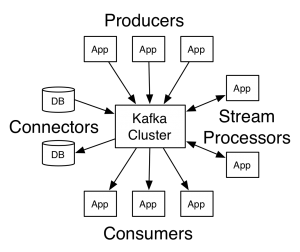
Apache Kafka efficiently processes the real-time and streaming data when implemented along with Apache Storm, Apache HBase and Apache Spark. Deployed as a cluster on multiple servers, Kafka handles its entire publish and subscribe messaging system with the help of four APIs, namely, producer API, consumer API, streams API and connector API. Its ability to deliver massive streams of message in a fault-tolerant fashion has made it replace some of the conventional messaging systems like JMS, AMQP, etc.
The major terms of Kafka’s architecture are topics, records, and brokers. Topics consist of stream of records holding different information. On the other hand, Brokers are responsible for replicating the messages. There are four major APIs in Kafka:
- Producer APIÂ – Permits the applications to publish streams of records.
- Consumer APIÂ – Permits the application to subscribe to the topics and processes the stream of records.
- Streams API – This API converts the input streams to output and produces the result.
- Connector API – Executes the reusable producer and consumer APIs that can link the topics to the existing applications.
Due to its widespread integration into enterprise-level infrastructures, monitoring Kafka performance at scale has become an increasingly important issue. Monitoring end-to-end performance requires tracking metrics from brokers, consumer, and producers, in addition to monitoring Zookeeper which is used by Kafka for coordination among consumers.There are currently several monitoring platforms to track Kafka performance, either open-source, like LinkedIn’s Burrow, or paid, like Data-dog. In addition to these platforms, collecting Kafka data can also be performed using tools commonly bundled with Java, including JConsole.
The above written is a brief about Apache Kafka. Watch out this space for latest trends in Technology.